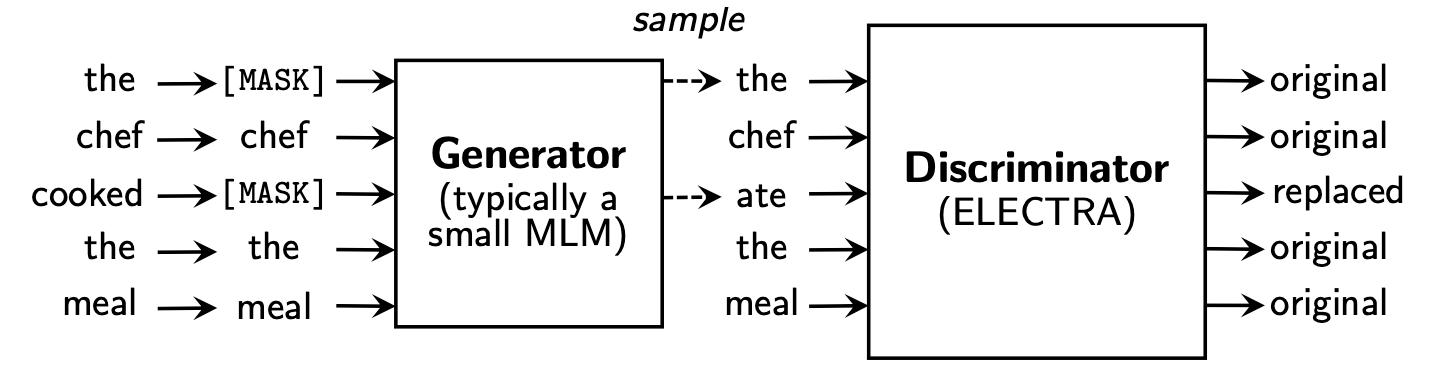
2주 간의 KoELECTRA 개발기 - 2부
2주 간의 KoELECTRA 개발을 마치고, 그 과정을 글로 남기려고 한다.
이 글을 읽으신 분들은 내가 했던 삽질(?)을 최대한 덜 하길 바라는 마음이다:)
2부에는 Pretraining, Finetuning 등을 다룰 예정이다.
Github Repo: https://github.com/monologg/KoELECTRA
Training
😀 드디어 모든 삽질들을 끝내고, Pretraining을 시작하였다 😀
Loss
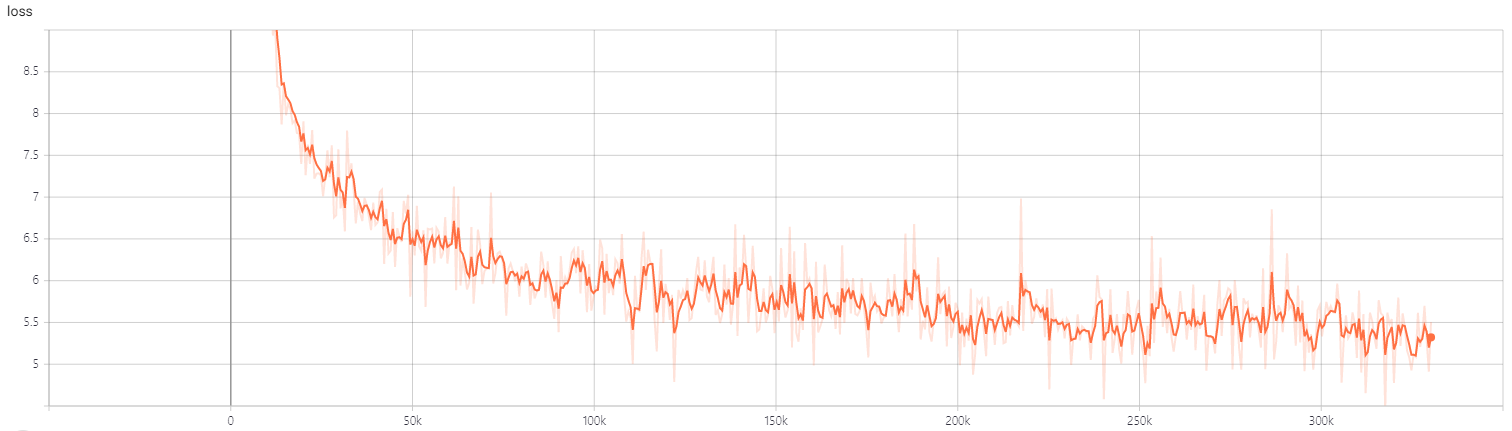
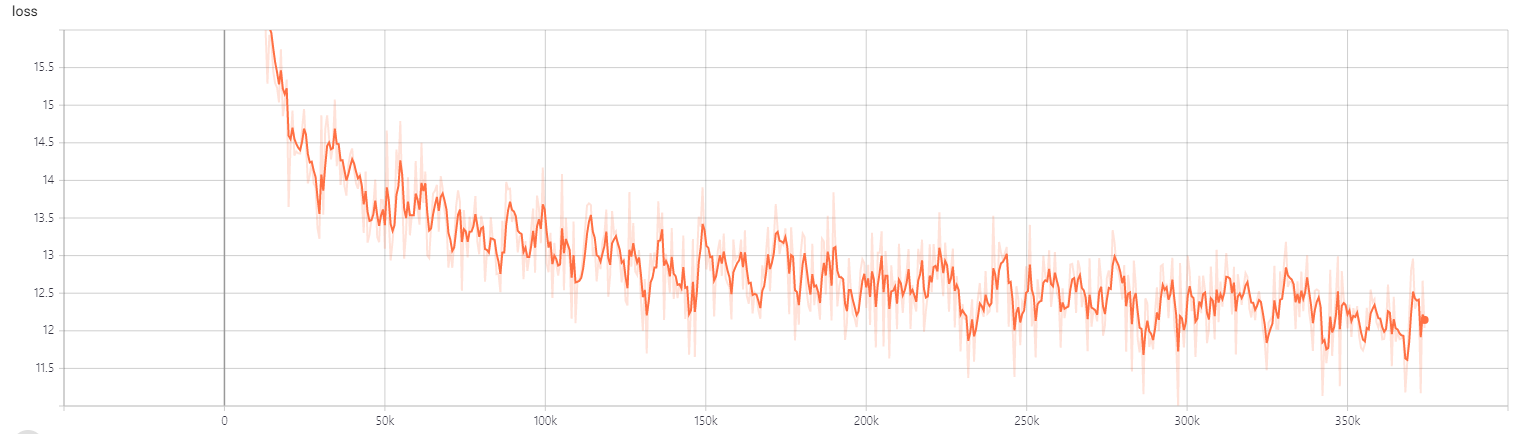
약 300k step 까지의 base와 small의 loss 추이이다. 첫 100k까지는 매우 빠르게 줄어들다가, 그 이후에는 조금씩 줄어드는 모습을 보인다.
Benchmark
학습 중간중간 성능 체크는 nsmc 데이터셋을 가지고 간단하게 평가하였다 (사실 GPU가 1개 밖에 없어 nsmc만 테스트한 건 비밀😢)
| Acc(%) | 25K | 75K | 90K | 125K | 150K | 250K | 300K | 450K |
|---|---|---|---|---|---|---|---|---|
Base |
88.10 | 88.48 | 88.67 | 88.92 | 88.97 | 89.51 | 89.65 | 90.16 |
Step이 증가할수록 accuracy가 오르는 것이 눈에 띄게 보이니 신기하긴 했다. (이것이 Pretraining의 힘인가….)
Training Time
데이터의 경우 14GB로 총 2.6B Token이다. BERT와 ELECTRA에서는 3.3B Token을 사용한 것에 비하면 데이터의 양이 조금 모자란 게 아쉽긴 하지만, 이것이 개인 단위에서 모을 수 있었던 최선의 데이터양이었다😵
TPU v3-8 기준으로 Base 모델은 약 7일, Small 모델은 약 3일이 소요되었다. 그래서 이 기간 동안 Finetuning 코드를 짜는 것으로 시간을 절약하였다.
Finetuning 코드 제작
코드의 경우는 Transformers의 Example 코드를 참고하여 제작하였다.
Finetuning의 경우 총 7개의 task에 대해 진행하였다. (때마침 얼마 전 카카오브레인에서 KorNLI와 KorSTS 데이터셋을 공개해주었다👍 1년 전과 비교했을 때 벤치마크를 평가할 수 있는 한국어 데이터셋이 많아진 것은 정말 좋은 일이라 할 수 있다.)
| NSMC | PAWS | QuestionPair | KorNLI | KorSTS | NaverNER | KorQuad | |
|---|---|---|---|---|---|---|---|
| Task | 감정분석 | 유사문장 | 유사문장 | 추론 | 유사문장 | 개체명인식 | 기계독해 |
| Metric | Acc | Acc | Acc | Acc | Spearman | F1 | EM/F1 |
기존의 연구들에서는 Bert-Multilingual-Cased를 가지고 많이 비교하였는데, 이번 연구에서는 XLM-Roberta-Base 모델로 평가를 시도하였다. 확실히 xlm-roberta가 bert보다는 성능이 좋았기에, 적어도 KoELECTRA가 xlm-roberta는 뛰어넘어야 유의미하지 않을까라고 생각해서 였다.
Deview에서 발표한 Larva의 경우 Benchmark pipeline을 만들어서 ckpt가 들어올 때마다 계속 evaluation을 해주었다고 하는데, 앞에서도 말했듯이 나에게는 GPU가 1개 밖에 없고, GCP에서 GPU를 많이 빌릴 수도 없기에 가장 최근 5개의 ckpt를 가지고 평가하였고, 그 중에서 평균값이 가장 좋았던 것을 최종 모델로 선정하였다.
Finetuning용 코드 및 사용법은 여기에서 직접 확인해볼 수 있다.
Convert from Tensorflow to Pytorch
Huggingface에서 ElectraModel을 구현하면서 tensorflow를 pytorch로 변환하는 코드도 함께 만들어줬다😍
관련 내용은 [내가 만든 ELECTRA를 Huggingface Transformers로 Porting하기]를 읽어보길 바란다. (여기서도 굉장히 삽질을 많이 해본 입장으로서 꼭 읽어보길 권한다)
Result
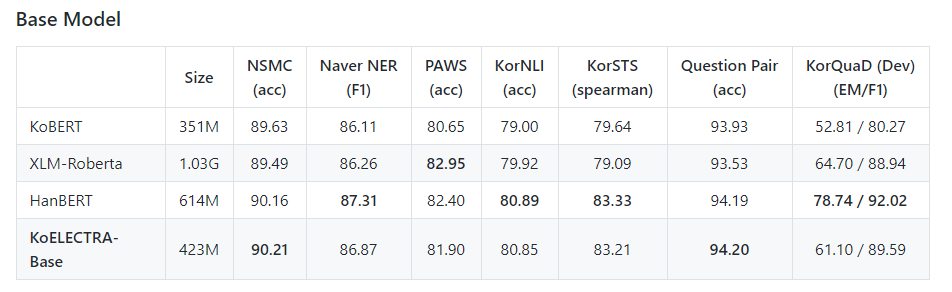
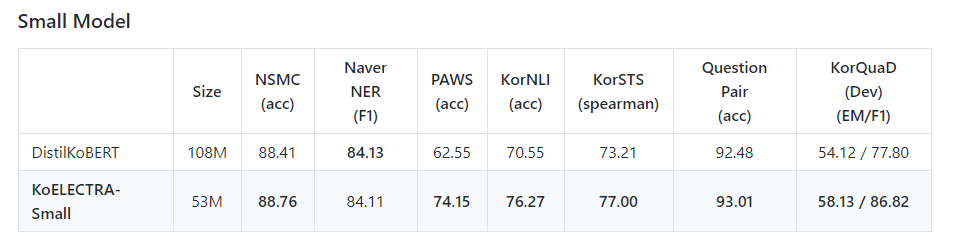
처음에 이 프로젝트를 계획할 때 가장 걱정되었던 점이 “성능이 안 나오면 어쩌나”였다. (성능이 너무 안 좋으면 사실 2주를 제대로 날린 셈이기에….)
결과는 예상했던 것보다 훨씬 좋았다. 애초에 데이터의 양이나 Tokenizer 등을 고려했을 때 HanBERT를 완벽히 따라잡는 것은 무리라고 생각했지만, KoBERT보다 전반적으로 성능이 많이 좋을 줄은 몰랐다. HanBERT와도 실질적인 결과는 비슷하거나 오히려 더 좋은 케이스도 있어서 이 정도면 🎉대성공🎉이라고 봐도 될 꺼 같다.
KoELECTRA-Small의 성능이 가장 인상적이었는데, 모델의 사이즈가 DistilKoBERT의 절반임에도 불구하고 우수한 성능을 보였다. 경량화 모델에서 충분히 사용할 만한 가치가 있을 것 같다.
How to Use
이 프로젝트를 처음 계획했을 때의 고려사항 중 아래 사항들이 가장 중요했었다.
“모든 OS에서 사용 가능”
“tokenization 파일을 만들 필요 없이 곧바로 사용 가능”
그리고 이제 transformers 라이브러리만 있으면 어떠한 환경에서도 한국어 PLM을 사용할 수 있게된 것이다🤗
$ pip3 install -U transformers |
from transformers import ElectraModel, ElectraTokenizer |
맺으며
솔직히 이렇게까지 반응이 좋을 줄은 몰랐다🙄 개발자로서 이럴 때가 가장 보람있지 않은가 싶다.
처음 계획할 때부터 “이거 만들면 다른 분들에게도 큰 도움이 되겠다”라 생각했는데, 실제로도 그런 것 같아 기분이 (굉장히) 좋다 😀
“내가 불편해하는 것은 분명 다른 누군가도 불편해한다. 그런 부분을 해결해주는 것이 개발자의 역할이라고 생각한다.”