BERT, ALBERT, ELECTRA 등을 직접 Pretrain하게 되면 모델이 Tensorflow의 ckpt 형태로 저장이 된다.
이번 글에서는 tensorflow ckpt를 transformers의 pytorch ckpt로 변환하는 법을 알아보겠다🤗
Intro
이번 글에서는 ELECTRA-Small을 기준으로 실습을 해본다. (BERT 등도 방법은 크게 다르지 않다)
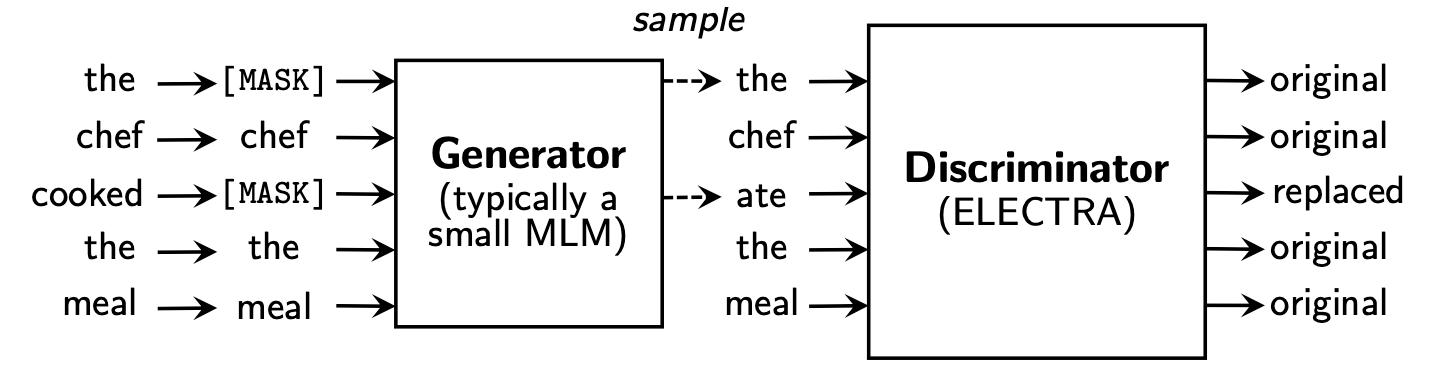
transformers v2.8.0을 기준으로 작성하였다. 이후 버전에서 호환되지 않는 경우가 있을 수 있다.Transformers의 ELECTRA는 discriminator와 generator를 각각 따로 만들어줘야 한다!
Prerequisite 1. Original Tensorflow Checkpoint 당연히 Tensorflow로 학습한 결과물 을 가지고 있어야 한다.
. ├── koelectra-small-tf │ ├── checkpoint │ ├── events.out.tfevents.1586942968.koelectra-small │ ├── graph.pbtxt │ ├── ... │ ├── model.ckpt-700000.data-00000-of-00001 │ ├── model.ckpt-700000.index │ └── model.ckpt-700000.meta └── ...
checkpoint model_checkpoint_path: "model.ckpt-700000" all_model_checkpoint_paths: "model.ckpt-600000" all_model_checkpoint_paths: "model.ckpt-625000" all_model_checkpoint_paths: "model.ckpt-650000" all_model_checkpoint_paths: "model.ckpt-675000" all_model_checkpoint_paths: "model.ckpt-700000"
주의할 점은 checkpoint 파일에서 model_checkpoint_path 값을 “원하는 step의 ckpt” 로 바꿔줘야 한다는 것이다.
2. config.json
(주의!) transformers 라이브러리가 업데이트되면서 API가 변경되는 경우가 있고, 이에 따라 config.json의 attribute가 추가/변경되는 경우가 있다.
https://huggingface.co/models 로 가서 대표 모델의 config.json을 보면서 직접 만들어야 한다.
vocab_size 변경에만 주의하면 충분함만일 max_seq_length를 바꿨다면 max_position_embeddings도 바꿔야 함
discriminator { "architectures" : ["ElectraForPreTraining" ], "attention_probs_dropout_prob" : 0.1 , "embedding_size" : 128 , "hidden_act" : "gelu" , "hidden_dropout_prob" : 0.1 , "hidden_size" : 256 , "initializer_range" : 0.02 , "intermediate_size" : 1024 , "layer_norm_eps" : 1e-12 , "max_position_embeddings" : 512 , "model_type" : "electra" , "num_attention_heads" : 4 , "num_hidden_layers" : 12 , "pad_token_id" : 0 , "type_vocab_size" : 2 , "vocab_size" : 32200 }
generator { "architectures" : ["ElectraForMaskedLM" ], "attention_probs_dropout_prob" : 0.1 , "embedding_size" : 128 , "hidden_act" : "gelu" , "hidden_dropout_prob" : 0.1 , "hidden_size" : 256 , "initializer_range" : 0.02 , "intermediate_size" : 1024 , "layer_norm_eps" : 1e-12 , "max_position_embeddings" : 512 , "model_type" : "electra" , "num_attention_heads" : 4 , "num_hidden_layers" : 12 , "pad_token_id" : 0 , "type_vocab_size" : 2 , "vocab_size" : 32200 }
3. tokenizer_config.json cased 모델의 경우 그냥 tokenizer를 load하면 매번 do_lower_case=False를 직접 추가해줘야 한다.
from transformers import ElectraTokenizertokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-small-discriminator" , do_lower_case=False )
tokenizer_config.json을 만들어주면 이러한 번거로움을 없앨 수 있다.max_seq_length가 128이면 model_max_length도 128로 바꿔주면 된다.)
tokenizer_config.json { "do_lower_case" : false , "model_max_length" : 512 }
4. vocab.txt tensorflow에서 학습했을 때 쓴 vocab.txt를 그대로 쓰면 된다.
5. 최종적인 디렉토리 형태 . ├── koelectra-small-tf │ ├── checkpoint │ ├── events.out.tfevents.1586942968.koelectra-small │ ├── graph.pbtxt │ ├── ... │ ├── model.ckpt-700000.data-00000-of-00001 │ ├── model.ckpt-700000.index │ └── model.ckpt-700000.meta │ ├── electra-small-discriminator │ ├── config.json │ ├── tokenizer_config.json │ └── vocab.txt │ ├── electra-small-generator │ ├── config.json │ ├── tokenizer_config.json │ └── vocab.txt └── ...
electra-small-discriminator와 electra-small-generator 폴더를 각각 만든다.config.json은 discriminator용과 generator용을 따로 만들어서 폴더 안에 넣는다.tokenizer_config.json과 vocab.txt는 discriminator와 generator 둘 다 동일한 파일 을 넣으면 된다.
Convert convert.py import osimport argparsefrom transformers.convert_electra_original_tf_checkpoint_to_pytorch import convert_tf_checkpoint_to_pytorchparser = argparse.ArgumentParser() parser.add_argument("--tf_ckpt_path" , type=str, default="koelectra-small-tf" ) parser.add_argument("--pt_discriminator_path" , type=str, default="koelectra-small-discriminator" ) parser.add_argument("--pt_generator_path" , type=str, default="koelectra-small-generator" ) args = parser.parse_args() convert_tf_checkpoint_to_pytorch(tf_checkpoint_path=args.tf_ckpt_path, config_file=os.path.join(args.pt_discriminator_path, "config.json" ), pytorch_dump_path=os.path.join(args.pt_discriminator_path, "pytorch_model.bin" ), discriminator_or_generator="discriminator" ) convert_tf_checkpoint_to_pytorch(tf_checkpoint_path=args.tf_ckpt_path, config_file=os.path.join(args.pt_generator_path, "config.json" ), pytorch_dump_path=os.path.join(args.pt_generator_path, "pytorch_model.bin" ), discriminator_or_generator="generator" )
Upload your model to Huggingface s3
먼저 huggingface.co 로 가서 회원가입 을 해야 함
아래의 명령어로 s3에 업로드 진행
$ transformers-cli login $ transformers-cli upload koelectra-small-discriminator $ transformers-cli upload koelectra-small-generator
Now Let’s Use It How to Use from transformers import ElectraModel, ElectraTokenizermodel = ElectraModel.from_pretrained("monologg/koelectra-small-discriminator" ) tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-small-discriminator" )
맺으며
사실 Model Porting과 관련하여 명확한 Documentation이 없어 나도 삽질을 상당히 했던 부분이다. 이번 내용이 다른 분들에게 도움이 되었으면 한다😛
또한 Huggingface s3에 모델을 업로드 하는 것은 꼭 사용해보길 권한다. 이 기능이 생긴지 얼마되지 않아서 모르시는 분들이 있는데, 업로드 용량의 제한도 없고 여러모로 라이브러리 사용도 편해진다. (모델을 100개 이상 올린다고 Huggingface 팀에서 뭐라고 하지 않으니 많이들 쓰셨으면ㅎㅎ)